Preliminaries
- Linear algebra
Hebb Rule1
Hebb rule is one of the earliest neural network learning laws. It was published in 1949 by Donald O. Hebb, a Canadian psychologist, in his work ’ The Organization of Behavior’. In this great book, he proposed a possible mechanism for synaptic modification in the brain. And this rule then was used in training the artificial neural networks for pattern recognition.

’ The Organization of Behavior’
The main premise of the book is that behavior could be explained by the action of a neuron. This was a relatively different idea at that time when the dominant concept is the correlation between stimulus and response by psychologists. This could also be considered a philosophy battle between ‘top-down’ and ‘down-top’.
“When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased”
This is a physical mechanism for learning at the cellular level. Dr. Hebb thought if two nerve cells were closed enough and they seemed related that was both of them fired simultaneously in high frequency. Then the connection between them would be strengthened. However, at that time, Dr. Hebb did not give firm evidence of his theory. The subsequent research in the next few years did prove the existence of this strengthening.
Hebb’s postulate is not completely new, because some similar ideas had been proposed before. However, Dr. Hebb gave a more systematic one.
Linear Associator
The first use of Hebb’s learning rule in artificial neural networks is a linear associator. Here is the simplest example of this neural network to illustrate the concept of Hebb’s postulate. A more complex architecture may drag us into the mire and miss the key points of the learning rule itself.
Linear associator was proposed by James Anderson and Teuwo Kohonen in 1972 independently. And its abbreviated notation is:
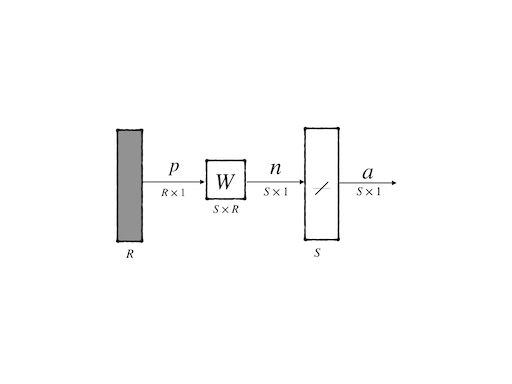
This architecture consists of a layer of \(S\) neurons each of which has \(R\) inputs and their transfer functions of them are all linear functions. So the output of this architecture can be simply calculated:
\[ a_i=\sum_{j=1}^{R}w_{ij}p_j\tag{1} \]
where the \(i\) th component of the output vector is given by the summation of all inputs weighted by the weights of the connections between the input and the \(i\) th neuron. Or, it also can be written in a matrix form:
\[ \mathbf{a}=\mathbf{W}\mathbf{p}\tag{2} \]
Associative memory is to learn \(Q\) pairs of prototype input/output vectors:
\[ \{\mathbf{p}_1,\mathbf{t}_1\},\{\mathbf{p}_2,\mathbf{t}_2\},\cdots,\{\mathbf{p}_Q,\mathbf{t}_Q\}\tag{3} \]
then the associator will output \(\mathbf{a}=\mathbf{t}_i\) crospending to input \(\mathbf{p}=\mathbf{p}_i\) for \(i=1,2,\cdots Q\). And when slight change of input occured(i.e. \(\mathbf{p}=\mathbf{p}_i+\delta\)), output should also change slightly( i.e. \(\mathbf{a}=\mathbf{t}_i+\varepsilon\)).
Review Hebb rule: “if neurons on both sides of the synapse are activated simultaneously, the strength of the synapse will increase”. And considering \(\mathbf{a}_i=\sum_{j=1}^{R}\mathbf{w}_{ij}\mathbf{p}_j\) where \(\mathbf{w}_{ij}\) is the weight between input \(\mathbf{p}_j\) and output \(\mathbf{a}_i\) so the mathematical Hebb rule is: \[ w_{ij}^{\text{new}} = w_{ij}^{\text{old}} + \alpha f_i(a_{iq}) g_j(p_{jq})\tag{4} \] where: - \(q\): the identification of training data - \(\alpha\): learning rate
This mathematical model uses two functions \(f\) and \(g\) to map raw input and output into suitable values and then multiply them as an increment to the weight of the connection. These two actual functions are not known for sure, so writing the functions as linear functions is also reasonable. Then we have the simplified form of Hebb’s rule:
\[ w_{ij}^{\text{new}} = w_{ij}^{\text{old}} + \alpha a_{iq} p_{jq} \tag{5} \]
A learning rate of \(\alpha\) is necessary. Because it can be used to control the process of update of weights.
The equation(5) does not only represent Hebb’s rule that the connection would increase when both sides of the synapses are active but also give other increments of connection when both sides of the synapses are negative. This is an extension of Hebb’s rule which may have no biological fact to support it.
In this post, we talk about the only supervised learning of Hebb’s rule. However, there is also an unsupervised version of Hebb’s rule which will be investigated in another post.
Recall that we have a training set:
\[ \{(\mathbf{p}_1,\mathbf{t}_1),(\mathbf{p}_2,\mathbf{t}_2),\cdots,(\mathbf{p}_Q,\mathbf{t}_Q)\}\tag{6} \]
Hebb’s postulate states the relationship between the outputs and the inputs. However, the outputs sometimes are not the correct response to inputs in some tasks. And as we know, in a supervised learning task correct outputs which are also called targets are given. So we replace the output of the model \(a_{iq}\) in equation(5) with the known correct output(target) \(t_{iq}\), so the supervised learning form of Hebb’s rule is: \[ w_{ij}^{\text{new}} = w_{ij}^{\text{old}} + \alpha t_{iq} p_{jq} \tag{7} \]
where: - \(t_{iq}\) is the \(i\) th element of \(q\)th target \(\mathbf{t}_q\) - \(p_{jq}\) is the \(j\) th element of \(q\)th input \(\mathbf{p}_q\)
of course, it also has a matrix form:
\[ \mathbf{W}^{\text{new}}=\mathbf{W}^{\text{old}}+\alpha\mathbf{t}_q\mathbf{p}_q^T\tag{8} \]
If we initial \(\mathbf{W}=\mathbf{0}\) , we would get the final weight matrix for the training set: \[ \mathbf{W}=\mathbf{t}_1\mathbf{p}_1^T+\mathbf{t}_2\mathbf{p}_2^T+\cdots+\mathbf{t}_Q\mathbf{p}_Q^T=\sum_{i=1}^{Q}\mathbf{t}_i\mathbf{p}_i^T\tag{9} \] or in a matrix form: \[ \mathbf{W}=\begin{bmatrix} \mathbf{t}_1,\mathbf{t}_2,\cdots,\mathbf{t}_Q \end{bmatrix}\begin{bmatrix} \mathbf{p}_1^T\\ \mathbf{p}_2^T\\ \vdots\\ \mathbf{p}_Q^T \end{bmatrix}=\mathbf{T}\mathbf{P}^T\tag{10} \]
Performance Analysis
Now let’s go into the inside of the linear associator mathematically. Mathematical analysis or mathematical proof can bring us strong confidence in the following implementation of Hebb’s rule.
\(\mathbf{p}_q\) are Orthonormal
Firstly, Considering the most special but simple case, when all inputs \(\mathbf{p}_q\) are orthonormal which means orthogonal mutually and having a unit length. Then with equation(10) the output corresponding to the input \(\mathbf{P}_q\) can be computed:
\[ \mathbf{a}=\mathbf{W}\mathbf{p}_k=(\sum^{Q}_{q=1}\mathbf{t}_q\mathbf{p}_q^T)\mathbf{p}_k=\sum^{Q}_{q=1}\mathbf{t}_q(\mathbf{p}_q^T\mathbf{p}_k)\tag{11} \]
for we have supposed that \(\mathbf{p}_q\) are orthonormal which means:
\[ \mathbf{p}_q^T\mathbf{p}_k=\begin{cases} 1&\text{ if }q=k\\ 0&\text{ if }q\neq k \end{cases}\tag{12} \]
from equation(11) and equation(12), we confirm that weights matrix \(\mathbf{W}\) built by Hebb’s postulate gives the right outputs when inputs are orthonormal.
The conclusion is that if input prototype vectors are orthonormal, Hebb’s rule is correct.
\(\mathbf{p}_q\) are Normal but not Orthogonal
More generally case is \(\mathbf{p}_q\) is not Orthogonal. And before putting them into an algorithm, we can convert every prototype vector into unit length without changing their directions. Then we have:
\[ \mathbf{a}=\mathbf{W}\mathbf{p}_k=(\sum^{Q}_{q=1}\mathbf{t}_q\mathbf{p}_q^T)\mathbf{p}_k=\sum^{Q}_{q=1}\mathbf{t}_q(\mathbf{p}_q^T\mathbf{p}_k)=\mathbf{t}_k+\sum_{q\neq k}\mathbf{t}_q(\mathbf{p}_q^T\mathbf{p}_k)\tag{13} \]
For us the vectors are normal but not orthogonal:
\[ \mathbf{t}_q\mathbf{p}_q^T\mathbf{p}_k=\begin{cases} \mathbf{t}_q & \text{ when } q = k\\ \mathbf{t}_q\mathbf{p}_q^T\mathbf{p}_k & \text{ when } q \nsupseteq k \end{cases}\tag{14} \]
then equation(13) can be also written as:
\[ \mathbf{a}=\mathbf{t}_k+\sum_{q\neq k}\mathbf{t}_q(\mathbf{p}_q^T\mathbf{p}_k)\tag{15} \]
if we want to produce the outputs of the linear associator as close as the targets, \(\sum_{q\neq k}\mathbf{t}_q(\mathbf{p}_q^T\mathbf{p}_k)\) should be as small as possible.
An example, when we have the training set:
\[ \{\mathbf{p}_1=\begin{bmatrix}0.5\\-0.5\\0.5\\-0.5\end{bmatrix},\mathbf{t}_1=\begin{bmatrix}1\\-1\end{bmatrix}\}, \{\mathbf{p}_2=\begin{bmatrix}0.5\\0.5\\-0.5\\-0.5\end{bmatrix},\mathbf{t}_1=\begin{bmatrix}1\\1\end{bmatrix}\} \]
then the weight matrix can be calculated:
\[ \begin{aligned} \mathbf{W}=\mathbf{T}\mathbf{P}^T=\begin{bmatrix} \mathbf{t}_1&\mathbf{t}_2 \end{bmatrix}\begin{bmatrix} \mathbf{p}_1^T\\\mathbf{p}_2^T \end{bmatrix} &= \begin{bmatrix} 1&1\\ -1&1 \end{bmatrix}\begin{bmatrix} 0.5&-0.5&0.5&-0.5\\ 0.5&0.5&-0.5&-0.5 \end{bmatrix}\\&=\begin{bmatrix} 1&0&0&-1\\ 0&1&-1&0 \end{bmatrix}\end{aligned} \]
we can, now, test these two inputs:
- \(\mathbf{a}_1=\mathbf{W}\mathbf{p}_1=\begin{bmatrix}1&0&0&-1\\0&1&-1&0\end{bmatrix}\begin{bmatrix}0.5\\-0.5\\0.5\\-0.5\end{bmatrix}=\begin{bmatrix}1\\-1\end{bmatrix}=\mathbf{t}_1\) Correct!
- \(\mathbf{a}_2=\mathbf{W}\mathbf{p}_2=\begin{bmatrix}1&0&0&-1\\0&1&-1&0\end{bmatrix}\begin{bmatrix}0.5\\0.5\\-0.5\\-0.5\end{bmatrix}=\begin{bmatrix}1\\1\end{bmatrix}=\mathbf{t}_2\) Correct!
Another example is when we have the training set:
\[ \{\mathbf{p}_1=\begin{bmatrix}1\\-1\\-1\end{bmatrix},\text{orange}\}, \{\mathbf{p}_2=\begin{bmatrix}1\\1\\-1\end{bmatrix},\text{apple}\} \]
firstly we convert target ‘apple’ and ‘orange’ into numbers: - orange \(\mathbf{t}_1=\begin{bmatrix}-1\end{bmatrix}\) - apple \(\mathbf{t}_1=\begin{bmatrix}1\end{bmatrix}\)
secondly, we normalize the input vector that would make them have a unit length:
\[ \{\mathbf{p}_1=\begin{bmatrix}0.5774\\-0.5774\\0.5774\end{bmatrix},\mathbf{t}_1=\begin{bmatrix}-1\end{bmatrix}\}, \{\mathbf{p}_2=\begin{bmatrix}0.5774\\0.5774\\-0.5774\end{bmatrix},\mathbf{t}_1=\begin{bmatrix}1\end{bmatrix}\} \]
then the weight matrix can be calculated:
\[ \begin{aligned} \mathbf{W}=\mathbf{T}\mathbf{P}^T=\begin{bmatrix} \mathbf{t}_1&\mathbf{t}_2 \end{bmatrix}\begin{bmatrix} \mathbf{p}_1^T\\\mathbf{p}_2^T \end{bmatrix} &= \begin{bmatrix} -1&1 \end{bmatrix}\begin{bmatrix} 0.5774&-0.5774&-0.5774\\ 0.5774&0.5774&-0.5774 \end{bmatrix}\\&=\begin{bmatrix} 0&1.1548&0 \end{bmatrix} \end{aligned} \]
we can, now, test these two inputs:
- \(\mathbf{a}_1=\mathbf{W}\mathbf{p}_1=\begin{bmatrix} 0&1.1548&0\end{bmatrix}\begin{bmatrix}0.5774\\-0.5774\\-0.5774\end{bmatrix}=\begin{bmatrix}-0.6668\end{bmatrix}=\mathbf{t}_1\) Correct!
- \(\mathbf{a}_2=\mathbf{W}\mathbf{p}_2=\begin{bmatrix} 0&1.1548&0\end{bmatrix}\begin{bmatrix}0.5774\\0.5774\\-0.5774\end{bmatrix}=\begin{bmatrix}0.6668\end{bmatrix}\)
\(\mathbf{a}_1\) is closer to \([-1]\) than \([1]\) so it belongs to \(\mathbf{t}_1\) And \(\mathbf{a}_2\) is closer to \([1]\) than \([-1]\) so it belongs to \(\mathbf{t}_2\). So, the algorithm gives an output close to the correct target.
There is another kind of algorithm that can deal with the task correctly rather than closely, for instance, the pseudoinverse rule can come up with another \(\mathbf{W}^{\star}\) which can give the correct answer to the above question.
Application of Hebb Learning
An application is proposed here. We have 3 inputs and outputs:
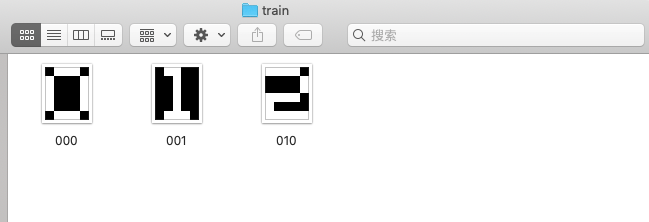
They are \(5\times 6\) pixels images that have only white and black pixels.



We then read the image and convert the white and black into \(\{1,-1\}\) so the ‘zero’ image change into the matrix: \[ \begin{aligned} \{&\\ &-1,1,1,1,-1,\\ &1,-1,-1,-1,1,\\ &1,-1,-1,-1,1,\\ &1,-1,-1,-1,1,\\ &1,-1,-1,-1,1,\\ &-1,1,1,1,-1\\ \}& \end{aligned} \]
we use the inputs as the target then the neuron network architecture become(transfer function is the hard limit):
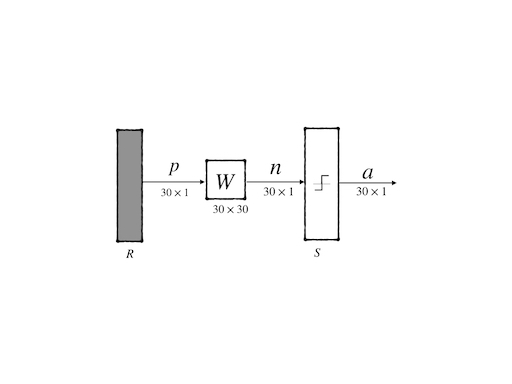
following the algorithm we summarized above we got the code:
# part of code
class HebbLearning():
def __init__(self, training_data_path='./data/train', gamma=0, alpha=0.5):
"""
initial function
:param training_data_path: the path of the training set and their labels.
They should be organized as pictures in '.png' form
:param gamma: the punishment coefficients
:param alpha: learning rate
"""
self.gamma = gamma
self.alpha = alpha
x = self.load_data(training_data_path)
self.X = np.array(x)
self.label = np.array(x)
self.weights = np.zeros((np.shape(x)[1], np.shape(x)[1]))
self.test_data = []
def load_data(self, data_path):
"""
load image data and transfer it into matrix form
:param data_path: the path of data
:return: a training set and targets respectively
"""
name_list = os.listdir(data_path)
X = []
for file_name in name_list:
data = cv2.imread(os.path.join(data_path, file_name), 0)
if data is None:
continue
else:
data = data.reshape(1, -1)[0].astype(np.float64)
for i in range(len(data)):
if data[i] > 0:
data[i] = 1
else:
data[i] = -1
data=data/np.linalg.norm(data)
X.append(data)
return X
def process(self):
"""
Comput weights using the Hebb learning function
:return:
"""
for x, label in zip(self.X, self.label):
self.weights = self.weights + self.alpha * np.dot(label.reshape(-1,1), x.reshape(1,-1)) - self.gamma*self.weights
def test(self, input_path='./data/test'):
"""
test function used to test a given input use the linear associator
:param input_path: test date should be organized as pictures whose names are their label
:return: output label and
"""
self.test_data = self.load_data(input_path)
labels_test = []
for x in self.test_data:
output_origin = np.dot(self.weights,x.reshape(-1,1))
labels_test.append(symmetrical_hard_limit(output_origin))
return np.array(labels_test)The whole project can be found: https://github.com/Tony-Tan/NeuronNetworks/tree/master/supervised_Hebb_learning please, Star it!
The algorithm gives the following result(left: input; right: output):



It looks like you have associate memory.
Some Variations of Hebb Learning
Derivate rules of Hebb learning are developed. And they overcome the shortage of Hebb learning algorithms, like:
Elements of \(\mathbf{W}\) would grow bigger when more prototypes are provided.
To overcome this problem, a lot of ideas came into mind:
- Learning rate \(\alpha\) can be used to slow down this phenomina
- Adding a decay term, so the learning rule is changed into a smooth filter: \(\mathbf{W}^{\text{new}}=\mathbf{W}^{\text{old}}+\alpha\mathbf{t}_q\mathbf{p}_q^T-\gamma\mathbf{W}^{\text{old}}\) which can also be written as \(\mathbf{W}^{\text{new}}=(1-\gamma)\mathbf{W}^{\text{old}}+\alpha\mathbf{t}_q\mathbf{p}_q^T\) where \(0<\gamma<1\)
- Using the residual between output and target to multipy input as the increasement of the weights: \(\mathbf{W}^{\text{new}}=\mathbf{W}^{\text{old}}+\alpha(\mathbf{t}_q-\mathbf{a}_q)\mathbf{p}_q^T\)
The second idea, when \(\gamma\to 1\) the algorithm quickly forgets the old weights. but when \(\gamma\to 0\) the algorithm goes back to the standard form. This idea of filter would be widely used in the following algorithms. The third method also known as the Widrow-Hoff algorithm, could minimize mean square error as well as minimize the sum of the square error. And this algorithm also has another advantage which is the update of the weights step by step whenever the prototype is provided. So it can quickly adapt to the changing environment while some other algorithms do not have this feature.
References
Demuth, H.B., Beale, M.H., De Jess, O. and Hagan, M.T., 2014. Neural network design. Martin Hagan.↩︎