Priliminaries
Extending Linear Regression with Features1
The original linear regression is in the form:
\[ \begin{aligned} y(\mathbf{x})&= b + \mathbf{w}^T \mathbf{x}\\ &=w_01 + w_1x_1+ w_2x_2+\cdots + w_{m+1}x_{m+1} \end{aligned}\tag{1} \]
where the input vector \(\mathbf{x}\) and parameter \(\mathbf{w}\) are \(m\)-dimension vectors whose first components are \(1\) and bias \(w_0=b\) respectively. This equation is linear for both the input vector and parameter vector. Then an idea come to us, if we set \(x_i=\phi_i(\mathbf{x})\) then equation (1) convert to:
\[ \begin{aligned} y(\mathbf{x})&= b + \mathbf{w}^T \mathbf{\phi}(\mathbf{x})\\ &=w_01 + w_1\phi_1(\mathbf{x})+\cdots + w_{m+1}\phi_{m+1}(\mathbf{x}) \end{aligned}\tag{2} \]
where \(\phi(\mathbf{x})=\begin{bmatrix}\phi_1(\mathbf{x})\\\phi_2(\mathbf{x})\\ \vdots\\\phi_m(\mathbf{x})\end{bmatrix}\) and \(\mathbf{w}=\begin{bmatrix}w_1\\w_2\\ \vdots\\ w_m\end{bmatrix}\) the function with input \(\mathbf{x}\), \(\mathbf{\phi}(\cdot)\) is called feature.
This feature function was used widely, especially in reducing dimensions of original input(such as in image processing) and increasing the flexibility of the predictor(such as in extending linear regression to polynomial regression).
Polynomial Regression
When we set the feature as:
\[ \phi(x) = \begin{bmatrix}x\\x^2\end{bmatrix}\tag{3} \]
the linear regression converts to:
\[ y(\mathbf{x})=b+ w_1x+w_2x^2\tag{4} \]
However, the estimation of the parameter \(\mathbf{w}\) is not changed by the extension of the feature function. Because in the least-squares or other optimization algorithms the parameters or random variables are \(\mathbf{w}\), and we do not care about the change of input space. And when we use the algorithm described in ‘least squares estimation’:
\[ \mathbf{w}=(X^TX)^{-1}X^T\mathbf{y}\tag{5} \]
to estimate the parameter, we got:
\[ \mathbf{w}=(\Phi^T\Phi)^{-1}\Phi^T\mathbf{y}\tag{6} \]
where \[ \Phi=\begin{bmatrix} -&\phi(\mathbf{x_1})^T&-\\ &\vdots&\\ -&\phi(\mathbf{x_m})^T&-\end{bmatrix}\tag{7} \]
Code for polynomial regression
To the same task in the ‘least squares estimation’, regression of the weights of the newborn baby with days is like:
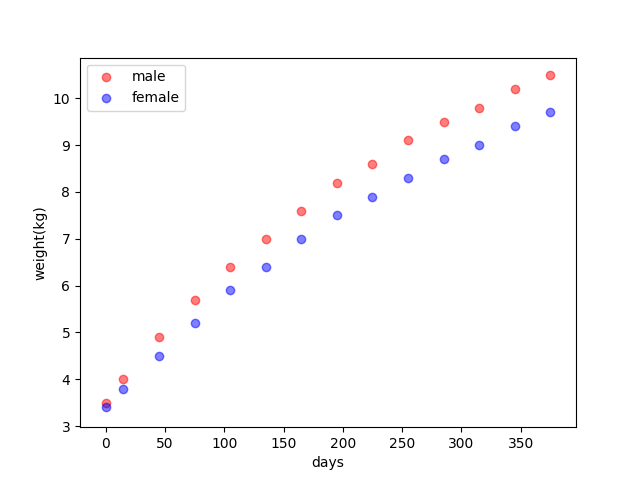
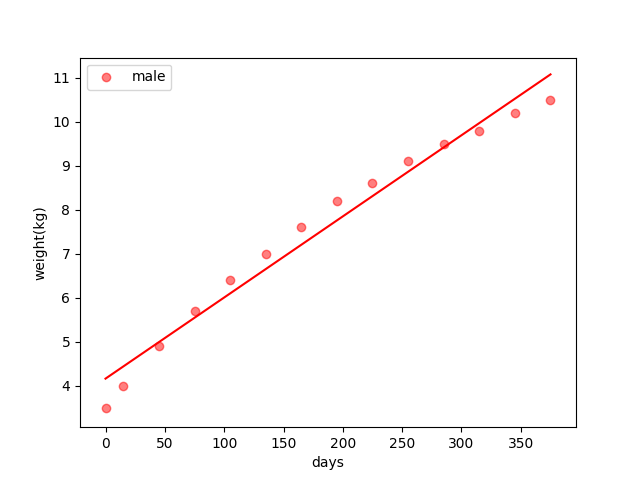
The linear regression result of a male baby is :
And code of the least square polynomial regression with power \(d\) is
def fit_polynomial(self, x, y, d):
x_org = np.array(x).reshape(-1, 1)
# add a column which is all 1s to calculate bias
x = np.c_[np.ones(x.size).reshape(-1, 1), x_org]
x_org_d = x_org
# building polynomial with highest power d
for i in range(1, d):
x_org_d = x_org_d * x_org
x = np.c_[x, x_org_d]
y = np.array(y).reshape(-1, 1)
w = np.linalg.inv(x.transpose().dot(x)).dot(x.transpose()).dot(y)
return wThe entire project can be found The entire project can be found https://github.com/Tony-Tan/ML and please star me.
And the result of the regression is:
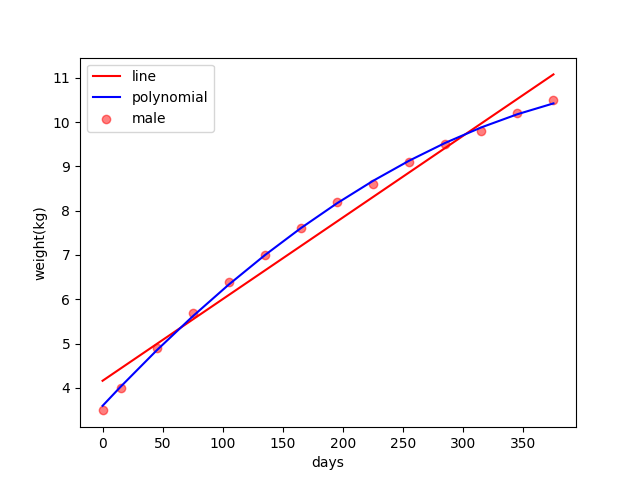
The blue regression line looks pretty well compared to the right line.
References
Bishop, Christopher M. Pattern recognition and machine learning. springer, 2006.↩︎