Preliminaries
- Perceptron learning algorithm
- Hebbian learning algorithm
- Linear algebra
Neural Network Training Technique1
Several architectures of the neural networks had been introduced. And each neural network had its own learning rule, like, the perceptron learning algorithm, and the Hebbian learning algorithm. When more and more neural network architectures were designed, some general training methods were necessary. Up to now, we can classify all training rules in three categories in a general way:
- Performance Learning
- Associative Learning
- Competitive Learning
The linear associator we discussed in ‘Hebbian Learning’ is a kind of associative learning, which is used to build a connection between two events. Competitive learning is a kind of unsupervised learning in which nodes(neurons) of the neural network compete for the right to respond to a subset of the input data.2
The main topic we are going to discuss today is Performance Learning which is a widely used training method in neural network projects. By the way, the categories of learning can be classified in different ways. This is not the only kind of classification.
Performance Learning and Performance Index
Training a network is to find suitable parameters for the model to meet our requirements for different tasks. If we can measure how suitable the neural network is for the task, we can then decide what to do next to modify the parameters. Performance learning is the procedure that modifies the parameters of neural networks by their performance based on certain measurements of the neural network performance.
The measurement of the performance we investigate here is called performance index and its appearance is called performance surface. What we should also be concerned about is the conditions for the existence of the minima or maxima. Because the minima or maxima decide the final result of the performance of the neural network for the task. In a word, what we need to do is to optimize the performance index by adjusting the parameters of the neural network with the information given by a training set(for different tasks).
Performance learning contains several different laws. And there are two common steps involved in the optimization process: 1. Define the ‘performance’ - a quantitative measure of network performance is called the performance index which has the properties when the neural network works well it has a lower value but when the neural network works poorly it has a larger value 2. Search parameters space to reduce the performance index
This is the heart of performance learning. We cloud also analyze the characteristics of the performance index before searching for the minima in the parameter space. Because, if the performance index we had selected did not meet the conditions of the existence of minima, searching for a minimum is just a waste of time. Or we can also set the additional condition to guarantee the existence of a minimum point.
Taylor Series
When we have a suitable performance index, what we need is a certain algorithm or a framework to deal with the optimization task. To design such a framework, we should study the performance index function first. Taylor series is a powerful tool to analyze the variation around a certain point of a function.
Scalar form function
\(F(x)\) is an analytic function which means derivatives of \(F(x)\) exist everywhere. Then the Taylor series expansion of point \(x^{\star}\) is:
\[ \begin{aligned} F(x)=F(x^{\star})&+\frac{d}{dx}F(x)|_{x=x^{\star}}(x-x^{\star})\\ &+\frac{1}{2}\frac{d^2}{d^2x}F(x)|_{x=x^{\star}}(x-x^{\star})^2\\ &\vdots \\ &+\frac{1}{n!}\frac{d^n}{d^nx}F(x)|_{x=x^{\star}}(x-x^{\star})^n \end{aligned}\tag{1} \]
This series with infinity items can exactly equal the origin analytic function.
If we only want to approximate the function in a small region near \(x^{\star}\), finite items in equation(1) are usually enough.
For instance, we have a function \(F(x)=\cos(x)\) when \(x^{\star}=0\), then:
\[ \begin{aligned} F(x)=\cos(x)&=\cos(0)-\sin(0)(x-0)-\frac{1}{2}\cos(0)(x-0)^2+\cdots\\ &=1-\frac{1}{2}x^2+\frac{1}{24}x^4+\cdots \end{aligned}\tag{2} \]
- \(0^{\text{th}}\) order approximation of \(F(x)\) near \(0\) is \(F(x)\approx F_0(x)=1\)
- \(1^{\text{st}}\) order approximation of \(F(x)\) near \(0\) is \(F(x)\approx F_1(x)=1+0\)
- \(2^{\text{nd}}\) order approximation of \(F(x)\) near \(0\) is \(F(x)\approx F_2(x)=1+0-\frac{1}{2}x^2\)
- \(3^{\text{rd}}\) order approximation of \(F(x)\) near \(0\) is \(F(x)\approx F_3(x)=1+0-\frac{1}{2}x^2+0\)
- \(4^{\text{th}}\) order approximation of \(F(x)\) near \(0\) is \(F(x)\approx F_4(x)=1+0-\frac{1}{2}x^2+0+\frac{1}{24}x^4\)
Odd number\(^{\text{th}}\) iterm is \(0\) because of the value of \(\sin(x)\) at \(0\) is \(0\)
And the \(0^{\text{th}},1^{\text{st}},2^{\text{nd}},3^{\text{rd}}\) and \(4^{\text{th}}\) approximation of \(F(x)\) looks like:
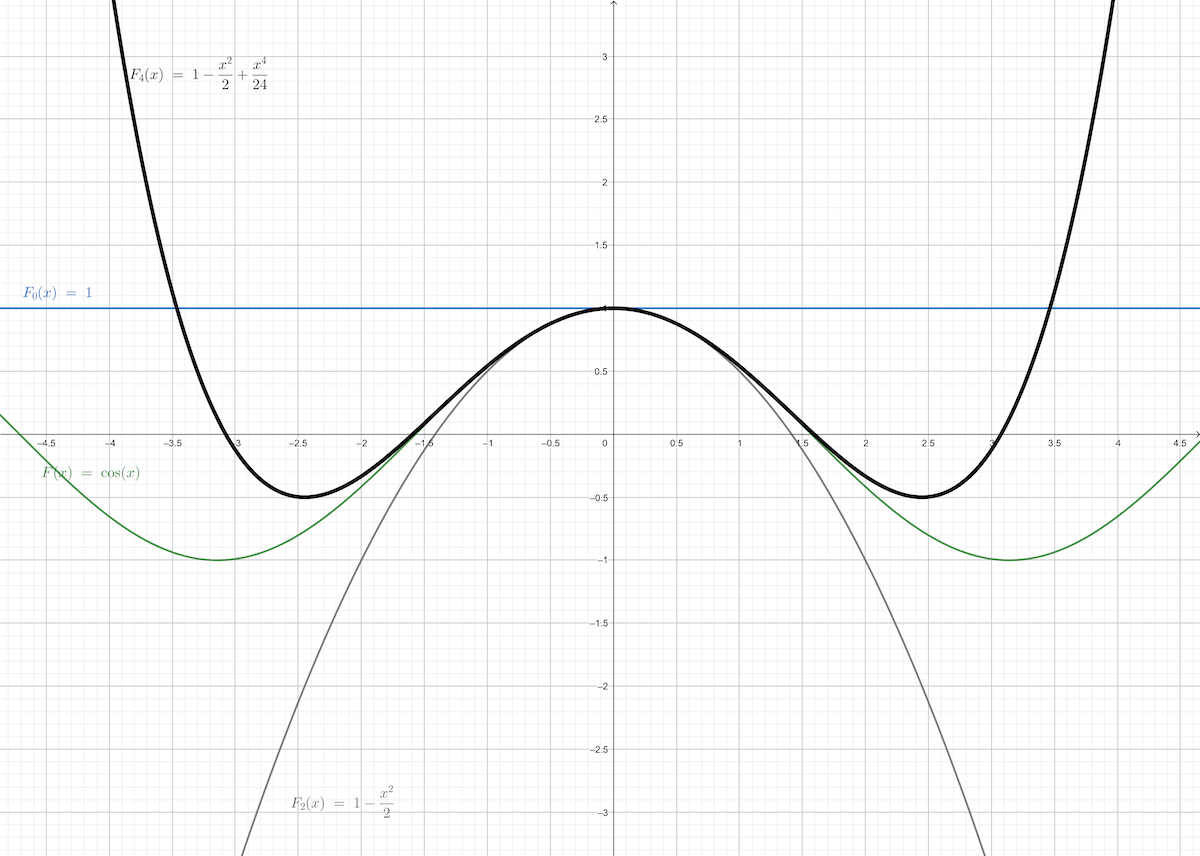
and, from the figure above we can observe that \(F_0(x)\) can only approximate \(F(x)\) at \(x^{\star}=0\) point. While in the interval between \(-1\) and \(+1\), \(F(x)\) can be precisely approximated by \(F_2(x)\). In a more wider interval like \([-1.6,+1.6]\) to approximate \(F(x)\), \(4^{\text{th}}\) order Taylor series are needed.
Then we can get the conclusion that if we want a certain precise extent in a relatively larger interval we need more items in the Taylor series. And we should pay attention to the interval out of the precise region, such as \(F_2(x)\) in the interval \((-\infty,-1]\cup [1,+\infty)\) are going away from \(F(x)\) as \(x\) moving away from \(x^{\star}=0\)
Vector form function
When the performance index is a function of a vector \(\mathbf{x}\), a vector from the Taylor series should be presented. And in the neural network, parameters are variables of the performance index so the vector from the Taylor series is the basic tool in performance learning. Function \(F(\mathbf{x})\) can be decomposed in any precise:
\[ \begin{aligned} F(\mathbf{x})=F(\mathbf{x}^{\star})& +\frac{\partial}{\partial x_1}F(\mathbf{x})|_{\mathbf{x}=\mathbf{x}^{\star}}(x_1-x_1^{\star})\\ &+\frac{\partial}{\partial x_2}F(\mathbf{x})|_{\mathbf{x}=\mathbf{x}^{\star}}(x_2-x_2^{\star})+\cdots\\ &+\frac{1}{2}\frac{\partial^2}{\partial^2 x_1}F(\mathbf{x})|_{\mathbf{x}=\mathbf{x}^{\star}}(x_1-x_1^{\star})^2\\ &+\frac{1}{2}\frac{\partial^2}{\partial x_1 \partial x_2}F(\mathbf{x})|_{\mathbf{x}=\mathbf{x}^{\star}}(x_1-x_1^{\star})(x_2-x_2^{\star}) +\cdots\\ &\vdots \end{aligned}\tag{3} \]
if we notate the gradient as : \[ \nabla F(x)=\begin{bmatrix} \frac{\partial F}{\partial x_1}\\ \frac{\partial F}{\partial x_2}\\ \vdots\\ \frac{\partial F}{\partial x_n} \end{bmatrix}\tag{4} \]
then the Taylor series can be written as: \[ \begin{aligned} F(\mathbf{x})=F(\mathbf{x}^{\star})&+(\mathbf{x}-\mathbf{x}^{\star})^T\nabla F(x)|_{\mathbf{x}=\mathbf{x}^{\star}}\\ &+\frac{1}{2}(\mathbf{x}-\mathbf{x}^{\star})^T\nabla^2 F(x)|_{\mathbf{x}=\mathbf{x}^{\star}}(x_1-x_1^{\star})\\ & \vdots \end{aligned}\tag{5} \]
The coefficients of the second-order item can be written in a matrix form, and it is also called the Hessian matrix:
\[ \nabla^2 F(x) = \begin{bmatrix} \frac{\partial^2}{\partial^2 x_1}&\cdots&\frac{\partial^2}{\partial x_1 \partial x_n}\\ \vdots&\ddots&\vdots \\ \frac{\partial^2}{\partial x_n \partial x_1}&\cdots&\frac{\partial^2}{\partial^2 x_n} \end{bmatrix}\tag{6} \]
Hessian matrix has many beautiful properties, such as it is always - Square matrix - Symmetric matrix
In the matrix, the elements on the diagonal are \(\frac{\partial^2 F}{\partial^2 x_i}\) is the \(2^{\text{nd}}\) derivative along the \(x_i\)-axis and in the gradient vector, \(\frac{d F}{d x_i}\) is the first derivative along the \(x_i\)-axis.
To calculate the \(1^{\text{st}}\) or \(2^{\text{nd}}\) derivative along arbitrary deriction \(\mathbf{p}\), we have: 1. \(1^{\text{st}}\)-order derivative along \(\mathbf{p}\) : \(\frac{\mathbf{p}^T\nabla F(\mathbf{x})}{||\mathbf{p}||}\) 2. \(2^{\text{nd}}\)-order derivative along \(\mathbf{p}\) : \(\frac{\mathbf{p}^T\nabla^2 F(\mathbf{x})\mathbf{p}}{||\mathbf{p}||^2}\)
For instance, we have a function \[ F(\mathbf{x})=x_1^2+2x_2^2\tag{7} \]
to find the derivative at \(\mathbf{x}^{\star}=\begin{bmatrix}0.5\\0.5\end{bmatrix}\) in the direction \(\mathbf{p}=\begin{bmatrix}2\\-1\end{bmatrix}\), we get the derivative at \(\mathbf{x}^{\star}=\begin{bmatrix}0.5\\0.5\end{bmatrix}\):
\[ \nabla F|_{\mathbf{x}=\mathbf{x}^{\star}} = \begin{bmatrix} \frac{\partial F}{\partial x_1}\\ \frac{\partial F}{\partial x_2} \end{bmatrix}\bigg|_{\mathbf{x}=\mathbf{x}^{\star}}=\begin{bmatrix} 2x_1\\ 4x_2 \end{bmatrix}\bigg|_{\mathbf{x}=\mathbf{x}^{\star}}=\begin{bmatrix} 1\\ 2 \end{bmatrix}\tag{8} \]
and the direction \(\mathbf{p}=\begin{bmatrix}2\\-1\end{bmatrix}\), the derivative is
\[ \frac{\mathbf{p}^T\nabla F(\mathbf{x}^{\star})}{||\mathbf{p}||}= \frac{\begin{bmatrix}2&-1\end{bmatrix} \begin{bmatrix}1\\2\end{bmatrix}}{\sqrt{2^2+(-1)^2}}=\frac{0}{\sqrt{5}}=0\tag{9} \]
\(0\) is a special number in the whole real numbers set. And the derivative is zero also meaningful in the optimization procedure. To find a zero slop direction we should solve the equation:
\[ \frac{\mathbf{p}^T\nabla F(\mathbf{x}^{\star})}{||\mathbf{p}||}=0\tag{10} \]
this means \(\mathbf{p}\) can not be \(\mathbf{0}\) because \(0\) length is illegle. And \(\mathbf{p}_{\text{unit}}=\frac{\mathbf{p}}{||\mathbf{p}||}\) is a unit vector along deriction \(\mathbf{p}\) so this can be written as:
\[ \mathbf{p}_{\text{unit}}^T\nabla F(\mathbf{x}^{\star})=0\tag{11} \]
which means \(\mathbf{p}_{\text{unit}}\) is orthogonal to gradient \(\nabla F(\mathbf{x}^{\star})\)
Another special deriction is which one has the greatest slop. Assuming the deriction \(\mathbf{p}_{\text{unit}}=\frac{\mathbf{p}}{||\mathbf{p}||}\) is the greatest slope, so:
\[ \mathbf{p}_{\text{unit}}^T\nabla F(\mathbf{x}^{\star})=||\mathbf{p}_{\text{unit}}^T|| \cdot ||\nabla F(\mathbf{x}^{\star})||\cos(\theta)\tag{12} \]
has the greatest value. We know this can only happen when \(\cos(\theta)=1\) which means the direction of the gradient has the greatest slop.
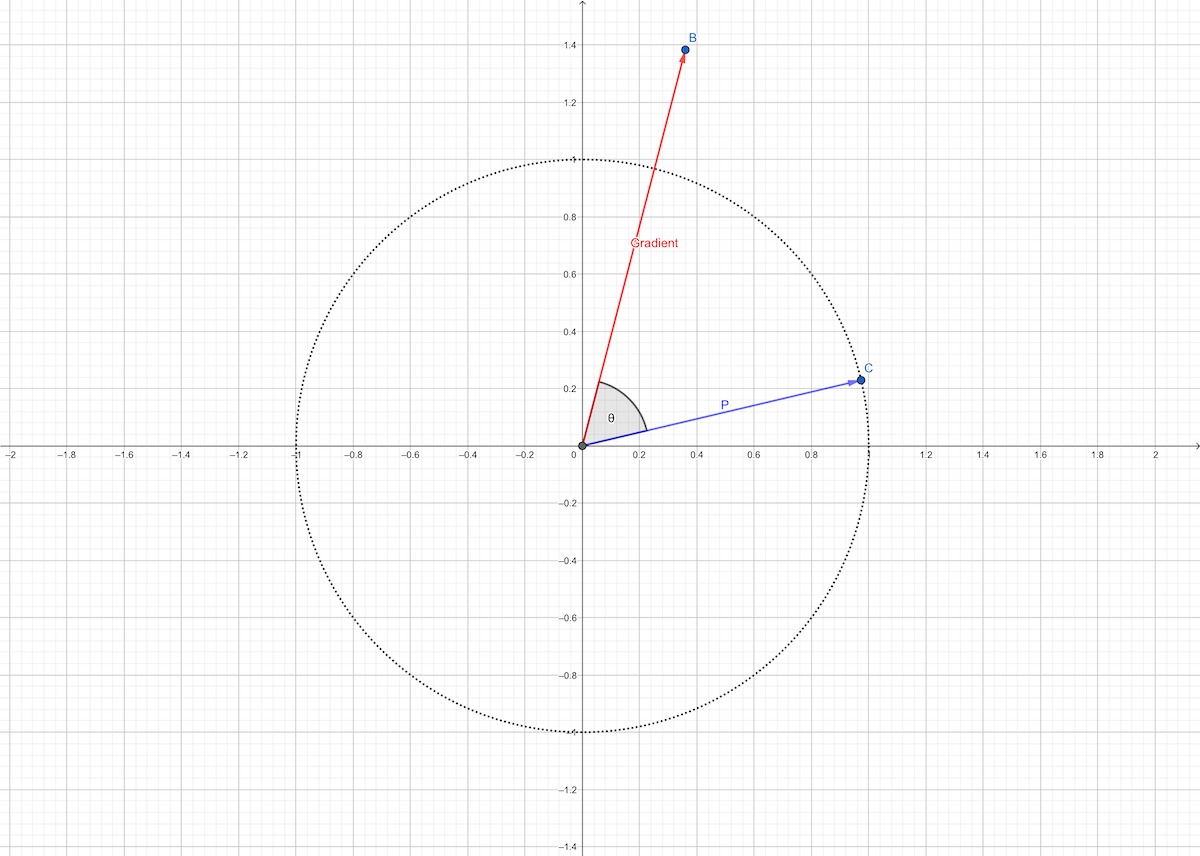
Necessary Conditions for Optimality
The main objective of performance learning is to minimize the performance index. So the condition of existence of a minimum performance index should be investigated:
- A strong minimum \(\mathbf{x}\) which mean in any deriction \(\mathbf{p}_{\text{unit}}\) around this point with a short distance \(\delta\) always has \(F(\mathbf{x})<F(\mathbf{x}+\delta \mathbf{p}_{\text{unit}})\), where \(\delta \to 0\)
- A weak minimum \(\mathbf{x}\) which mean in any deriction \(\mathbf{p}_{\text{unit}}\) around this point with a short distance \(\delta\) always has \(F(\mathbf{x})\leq F(\mathbf{x}+\delta \mathbf{p}_{\text{unit}})\), where \(\delta \to 0\)
- Global minimum is the minimum one of all weak or strong minimum sets.
For instance,
\[ F(x)=3x^4-7x^2-\frac{1}{2}x+6\tag{13} \]
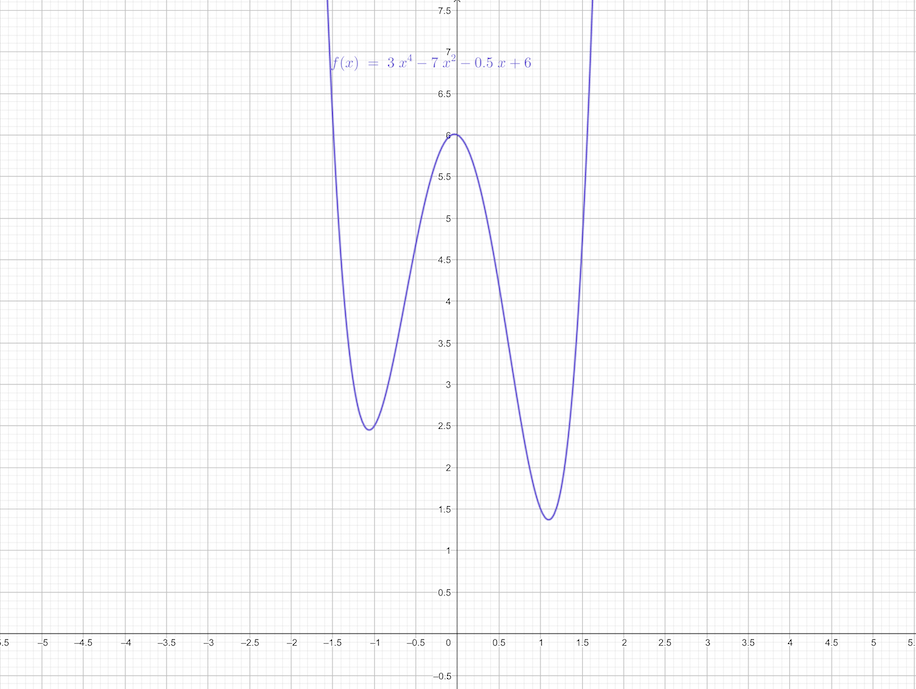
- 2 local minimums at near \(x_1=-1.1\) and near \(x_2=1.1\)
- near \(x_2=1.1\) gives the global minimum
If the variable of function is a vector:
\[ F(\mathbf{x})=(x_2-x_1)^4+8x_1x_2-x_1+x_2+3\tag{14} \]
and it looks like this:
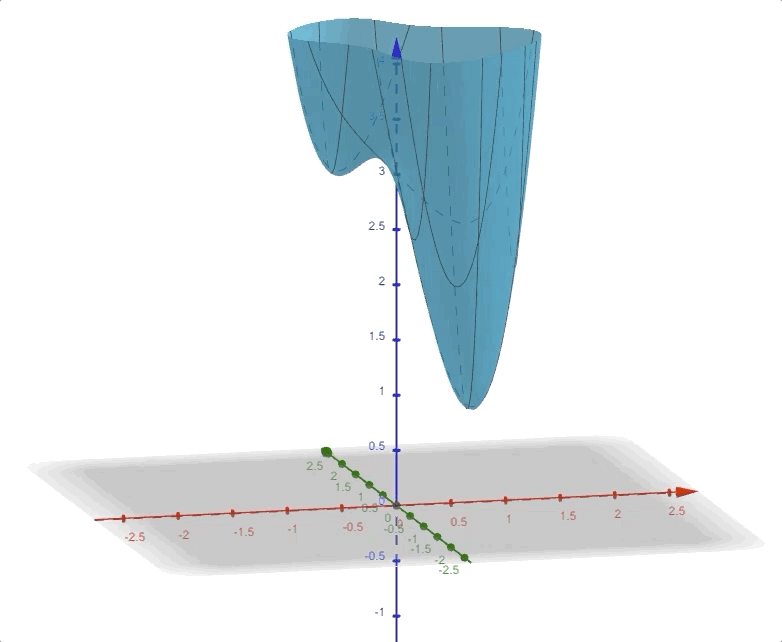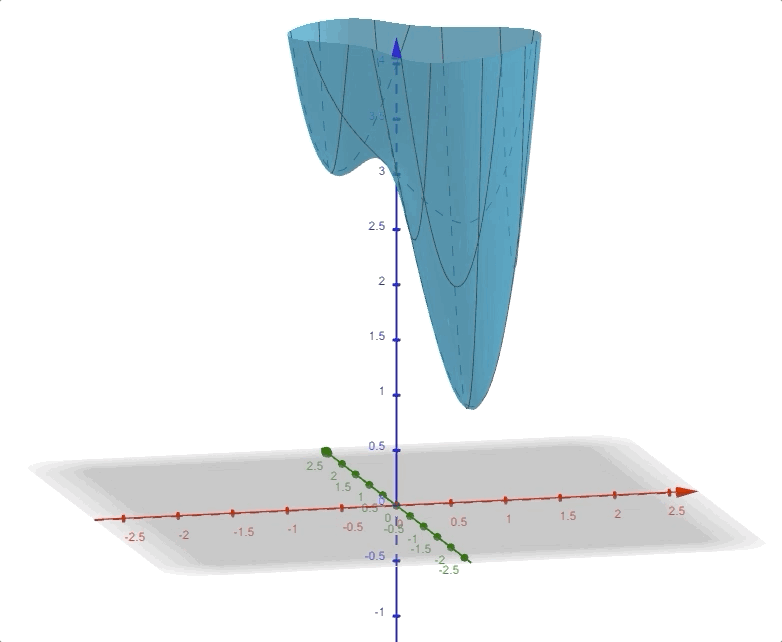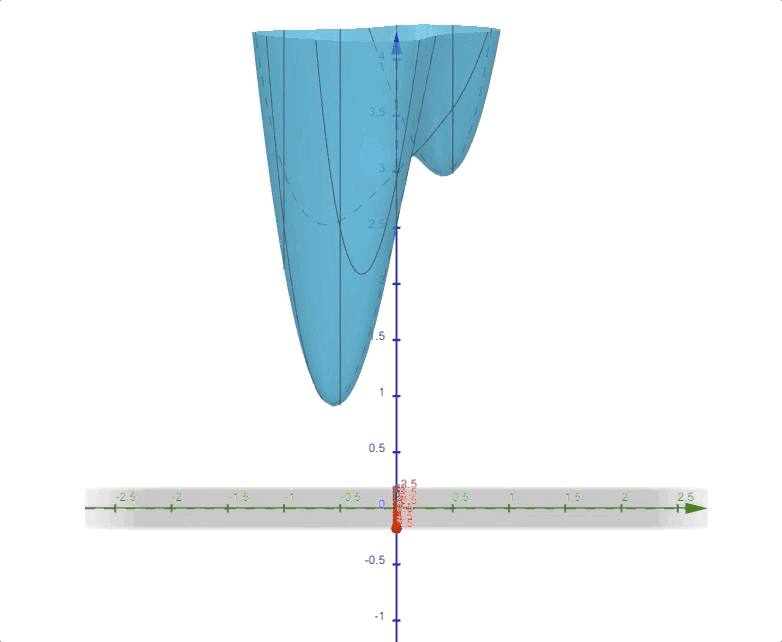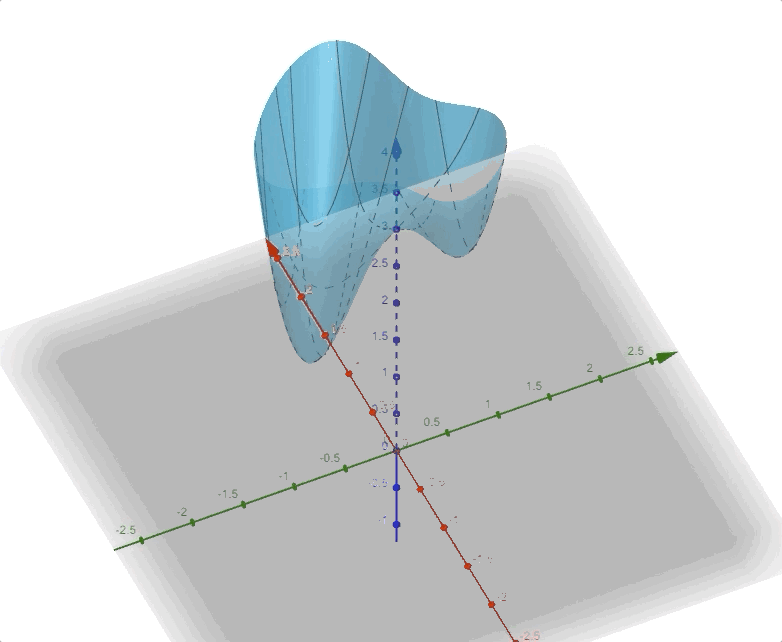
in 3-D space. And the contour plot of this function is:
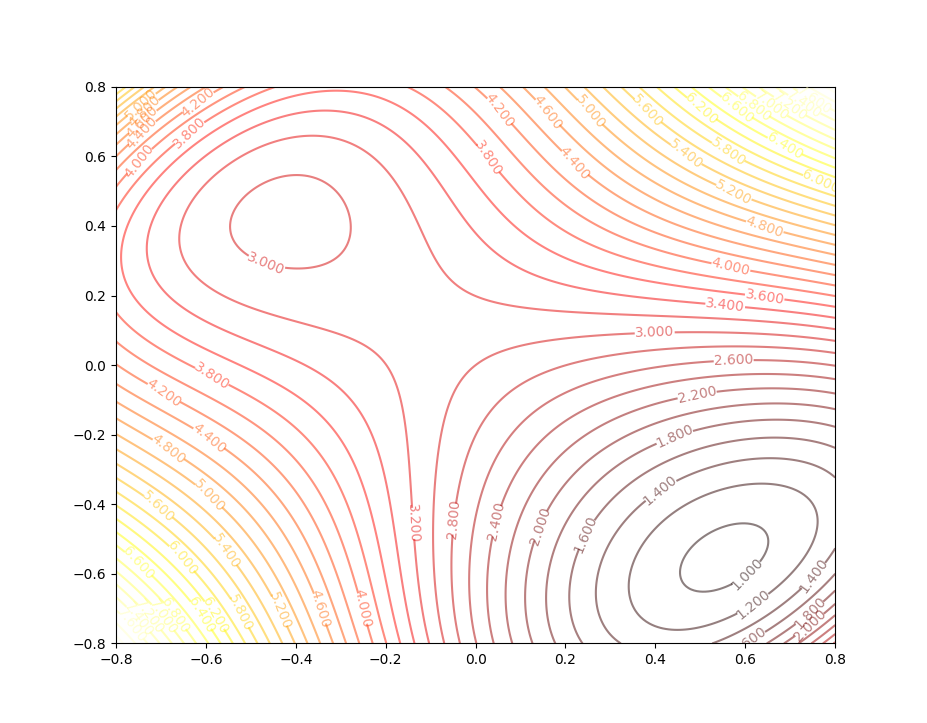
There are three points in this contour figure:
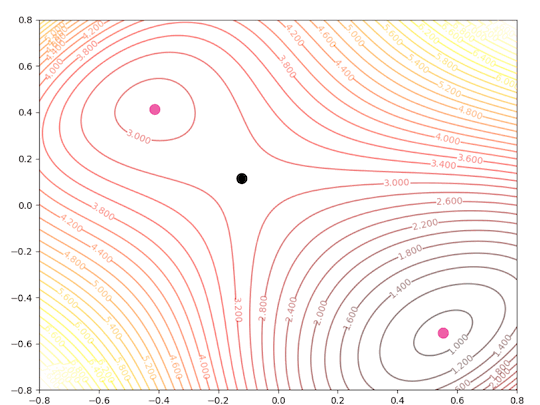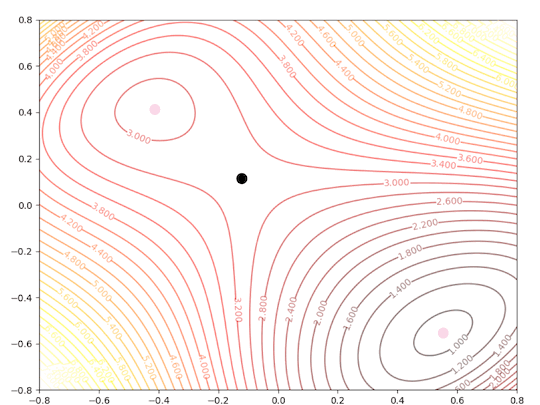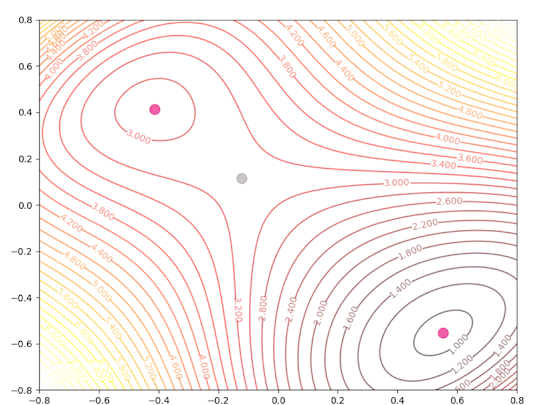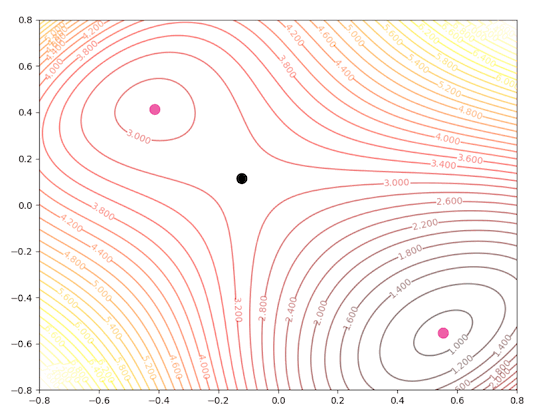
and the pink points are the two local minimums, and the black points are called a saddle points.
These two examples illustrate the minimum points and saddle points. But what conditions are needed to confirm the existence?
First-order Conditions
Go back to the Taylor series with \(\Delta x=x-x^{\star}\neq 0\), the first item of the series is taken into account:
\[ \begin{aligned} F(x)&=F(x^{\star})+\frac{d}{dx}F(x)|_{x=x^{\star}}(x-x^{\star})\\ F(x^{\star}+\Delta x)&=F(x^{\star})+\nabla F(x)\Delta x \end{aligned}\tag{15} \]
when \(x^{\star}\) is a candidate of minimum point, we want:
\[ F(x^{\star}+\Delta x)\geq F(x^{\star})\tag{16} \]
so, in equation(15), \[ \nabla F(x)\Delta x\geq 0 \tag{17} \]
are needed. Considering another direction, if \(x^{\star}\) is the minimum point, it also has:
\[ F(x^{\star}-\Delta x)=F(x^{\star})-\nabla F(x)\Delta x\geq F(x^{\star})\tag{18} \]
then
\[ \nabla F(x)\Delta x\leq 0 \tag{19} \]
To satisfy both equation(17) and equation(19) if and only if
\[ \nabla F(x)\Delta x=0\tag{20} \]
Because \(\Delta x\neq 0\), so we must have \(\nabla F(x)\) when \(x\) is the minimum point. \(\nabla F(x)=0\) is a necessary but not sufficient condition. The first-order condition has been concluded above.
Second-order Condition
The first-order condition does not give a sufficient condition. Now let’s consider the second-order condition. With \(\Delta\mathbf{x}=\mathbf{x}-\mathbf{x}^{\star}\neq \mathbf{0}\) and gradient equal to \(\mathbf{0}\), and take them into equation(5) . Then the second-order Taylor series is:
\[ F(\mathbf{\Delta\mathbf{x}-\mathbf{x}^{\star}})=F(\mathbf{x}^{\star})+\frac{1}{2}\Delta\mathbf{x}^T\nabla^2 F(x)|_{\mathbf{x}=\mathbf{x}^{\star}}\Delta\mathbf{x}\tag{21} \]
When \(||\Delta\mathbf{x}||\) is small, zero-order, first-order, and second-order terms of the Taylor series are precise enough to approximate the original function. When \(F(\mathbf{x}^{\star})\) is a strong minimum, the second-order item should be:
\[ \frac{1}{2}\Delta\mathbf{x}^T\nabla^2 F(x)|_{\mathbf{x}=\mathbf{x}^{\star}}\Delta\mathbf{x}>0 \]
Recalling linear algebra knowledge, positive definite matrix \(A\) is:
\[ \mathbf{z}^T A \mathbf{z}>0 \text{ for any } \mathbf{z} \]
and positive semidefinite matrix \(A\) is:
\[ \mathbf{z}^T A \mathbf{z}\geq0 \text{ for any } \mathbf{z} \]
So when the gradient is \(\mathbf{0}\) and the second-order derivative is positive definite(semidefinite), this point is a strong(weak) minimum. And positive definite Hessian matrix is a sufficient condition to a strong minimum point, but it’s not a necessary condition. Because when the Hessian matrix is \(0\) the third-order item has to be calculated.